Most people in IT have never experienced the dread of watching a revenue graph go flat at 11 PM on a Saturday. It’s not slow or declining. It’s flat, like someone unplugged the country. That is the job.
The False Expectation Problem
When I began working in iGaming infrastructure, I thought it would be a sophisticated fortress of backup systems, cutting-edge tech, and engineers who had seen it all. It was the kind of setup that exists in the minds of those who have never been inside one.
The reality is more interesting and sobering. Much of it is surprisingly basic. Standard hardware and software. The same Linux distributions you use at home. The same databases everyone else has. The sophistication isn't in the tech stack; it’s in the people operating it and the procedures they follow at 3 AM when everything is on fire and someone in a suit is sending frantic messages.
I mention this not to dismiss anyone but because I spent a long time measuring myself against an imaginary standard that didn’t exist. The infrastructure is simple in places because simple works. Simple is easy to debug. Simple doesn’t surprise you in ways you can’t recover from. The complexity lies in the operational layer, the interactions between systems, and the failures you've seen before as well as those you haven't, but know are coming.
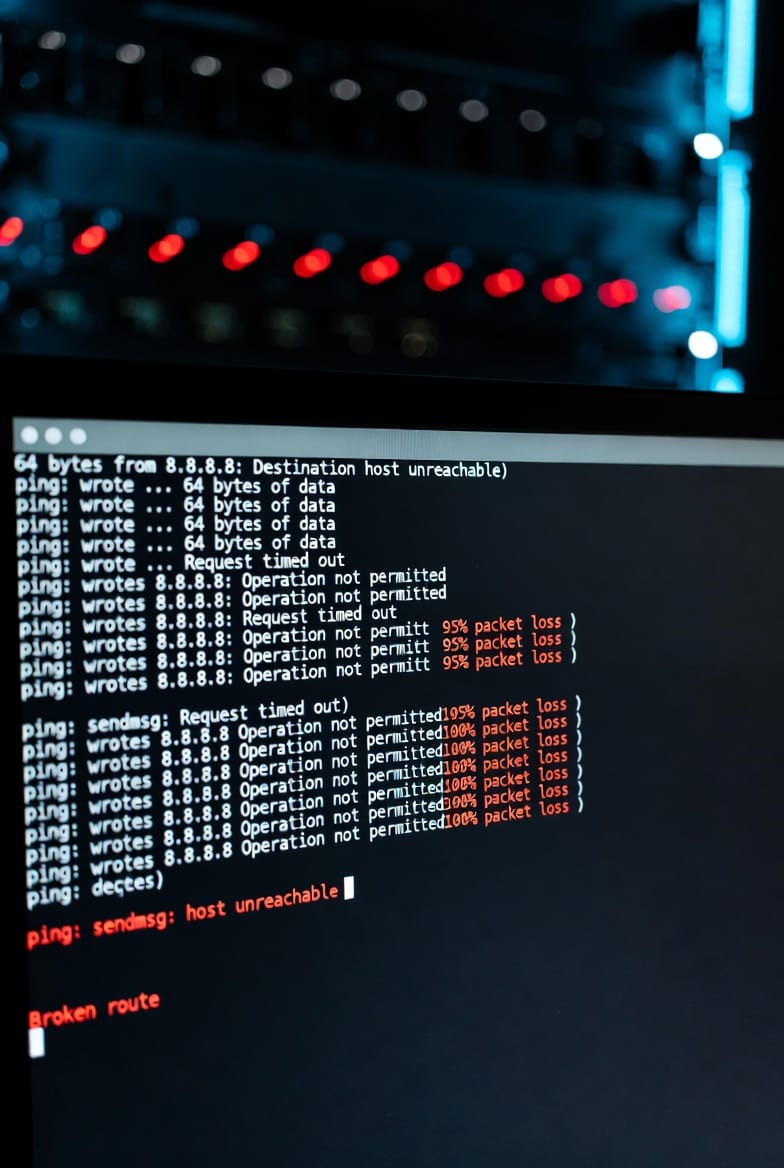
The Cloudflare Saturday
The worst type of outage isn't the one you caused. If you caused it, you can fix it. You know what you did. You roll back, restore, and write the post-mortem. You learn from it and don’t make that mistake again.
The worst type is the one that hits from upstream, like bad weather. You did everything right. Your infrastructure is healthy. Your monitoring shows everything green. Then Cloudflare experiences an issue and takes down half the internet, including all your customer-facing properties.
You might still have out-of-band connections working, but everything else is gone. Global outage. Not your fault, but still your problem.
You make the call. You open the incident. You watch the Cloudflare status page refresh, hoping for better news. You update stakeholders with information you don’t have yet because silence during an outage is somehow worse than admitting you don't know what’s happening. You handle calls and remain calm, even if internally you’re calculating how many transactions per second are being lost during this crisis.
Eventually, everything comes back. It always does. You document what happened and add it to the list of things that can occur outside your control. You ensure your redundancy covers more of that list than before.
The nmap Incident
I’ve seen many things cause outages. Hardware failures, misconfigurations, and forgotten certificate expirations that someone was sure were monitored. There’s also the classic 3 AM change window when someone tests something new.
However, the most memorable incident involved a senior network architect who ran nmap from within a core router and let's just say, BGP did not like that.
I’ll leave the technical details for you to discover, but if you understand why that’s a catastrophic idea, you’re probably the right fit for this work. If you’re googling what BGP is, this might not be the job for you. No judgment; different roles suit different people.
The lesson isn’t that senior engineers make mistakes because they do, and everyone does. The real lesson is that in iGaming infrastructure, the impact of a mistake isn’t just a broken feature or a slow page load. It’s immediate, measurable, and quantifiable in a way everyone in the room understands.
The 03:00 Phone Call
You learn to accept the possibility of costing someone millions. It sounds harsh, but it’s a healthy adjustment. The alternative is paralysis, and being paralyzed during an outage can cost even more than the outage itself.
What you really do is create procedures before you need them. Redundant links. Out-of-band access. Starlink as a backup for your backup. Runbooks tailored for someone who has been awake for six hours and had two cups of coffee that aren't working anymore. Escalation paths that don’t depend on anyone being available who might not be.
Prevention is the job. Detection is a backup plan. Recovery is the last resort. You invest your energy in prevention because the other two options are costly in many ways beyond just finances.
Contractual clauses help, not because they make the outage less stressful, but because they structure the conversation afterward. You follow a process created by those who have had this talk before, ensuring it doesn’t turn into a shouting match.
It mostly works.
What This Teaches You That Normal IT Never Would
Running corporate IT teaches you to keep systems running for users who will complain loudly if their email is slow. That’s valuable experience, and it prepares you for some of what follows.
However, it doesn’t prepare you for the infrastructure where the cost of being wrong is immediate, specific, and apparent to everyone in the room. It doesn’t prepare you for making changes to production systems that cannot go offline, aren’t scheduled for maintenance windows, and are being used by someone right now in a different time zone who doesn’t know you exist—and wants it to stay that way.
The Honest Summary
iGaming infrastructure isn’t necessarily more technically complex than other fields, sometimes it’s less so. What sets it apart is the operational pressure, financial consequences, and cultural expectation that things simply do not go down, not mostly do not go down, and not usually do not go down.
Do not go down.
You’ll either find that clarity refreshing or intolerable. Both responses are valid. Those who find it clarifying tend to stick around. Those who find it intolerable often leave after their first major incident, typically citing work-life balance, which is a fair and reasonable choice.
This work is not for everyone. The people it is for tend to recognize it the first time they keep something running that shouldn’t still be up.